More than just chatbots: Using context to build the future of in-app AI experiences
- January 30, 2024
- 11 min read
Today, text-driven, turn-based chatbots dominate AI experiences.
At Dopt, we believe there’s a much more interesting problem to solve: building in-app AI assistants. We believe there’s a huge opportunity to help users learn, navigate, and use the interfaces they already work within. What if we could create AI assistants that offer contextual help seamlessly integrated into a user’s experience without the user ever needing to think about a prompt?
In this deep dive, we’ll investigate how we might build such experiences and the technical architectures and product considerations that come with them.
First, we’ll walk through why chatbots might not be the future and explore what alternate models of embedded assistance might look like.
Next, we’ll define contexts and how they work in these kinds of systems, and we’ll determine which contexts we want to gather for building in-app assistants.
Then, we’ll outline a retrieval architecture built on custom embeddings to find the most relevant signals for a user’s queries and contexts, and we’ll cover a generation architecture which uses a system of multimodal prompts to craft a meaningful response.
Finally, we’ll highlight a few of our key learnings from building these in-app AI experiences ourselves.
Why not embedded chatbots?
We can start forming a better mental model of in-app assistance by asking why we should restrict ourselves to using natural language conversations as our medium for AI assistance.
As Amelia Wattenberger deftly explains in her article, Boo Chatbots: Why Chatbots Are Not the Future:
Natural language is great at rough direction: teleport me to the right neighborhood. But once ChatGPT has responded, how do I get it to take me to the right house?
We’ve all experienced the struggle to create precise prompts about an app when writing questions to a chatbot. And, even more, we’ve all struggled to translate those answers back into the steps we need to take to be successful.
Specifically, existing embedded chat experiences suffer in three key ways:
- prompting is imprecise and very chaotic in the sense that small changes in prompts cause a huge change in answers
- the user (the question-asker) is burdened with solving the problem of identifying and producing all relevant context for their question
- questions and answers are not integrated into the app itself but instead surfaced indirectly in separate and often disruptive UIs
At Dopt, we believe that by tackling these problems, we can radically alter how in-app assistance works.
Exploring alternate models of embedded in-app assistance
Within an app, a user’s interactions can follow many distinct paths — they might navigate pages by clicking on a link, they might close an announcement modal, or they might type something into a search box. All of these interaction paths are valuable inputs into an in-app assistant.
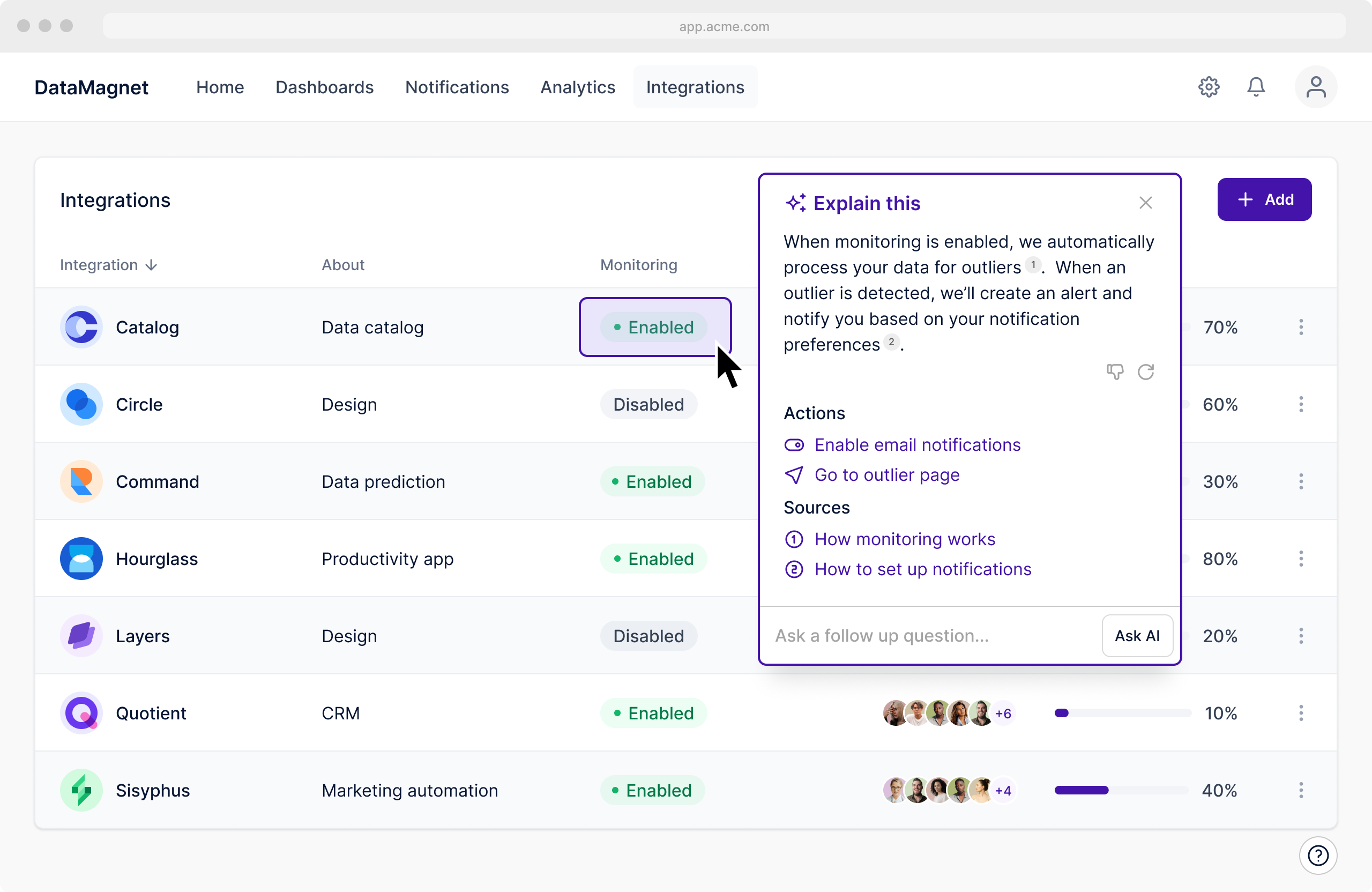
Consider the design exploration in the video above where a user wants to know what the Enabled status refers to. The user might’ve been able to make progress through a chatbot, but their journey would’ve been a lot more circuitous. They would likely need to explain the Enabled selector and situate it within the Monitoring column of the Integrations page. After that, they’d need to carefully create a prompt about the action to get a consistent answer.
In our exploration, we propose a different solution. We consider how we can use context from the page (for example, that it’s the Integrations page), from the DOM (that the user is interacting with an Enabled chip in the Monitoring column of a table), and from a screenshot of the page to ground the answer in the user’s frame of reference. This helps generate a targeted and helpful answer with accompanying sources and related next steps. We also consider continuations (”Ask a follow up question…”) where a user can ask further questions which are still grounded in the same context.
This exploration highlights an alternate and potentially more valuable model for in-app assistance. By leveraging static context like sources alongside in-app context like user and company properties, DOM and app state, and visual UI screenshots, we can offer accessible and actionable responses embedded within apps themselves.
Briefly defining context
Before we jump into architecture, we should first clearly define context. Within a search (or any other question-answer) system, we can define contexts as sets of information that help enrich and complete a user’s potentially under-specified query.
Say a user enters the following query: “weather tomorrow”. Our system needs to gather two key pieces of information, a where and a when: where is the user asking for the weather and when is the user asking about. The when is pretty easy — requests from a browser or device will come with information on the client’s local time, so “tomorrow” can be replaced with the following day according to the local time. The where is harder — if a browser or device permits an application to gather geolocation information, our system could use that. Otherwise, we’ll have to rely on substitutes like using the request’s IP Address or combing through the user’s history.
Even with these harder cases and substitutes, being able to identify a user’s time and geolocation to provide the most likely weather produces a better experience than asking the user for clarification. The context-less journey, the one where the user has to add additional inputs or take extra steps, is easier to build because it requires exact specification, but it’s also less rewarding and definitely less magical.
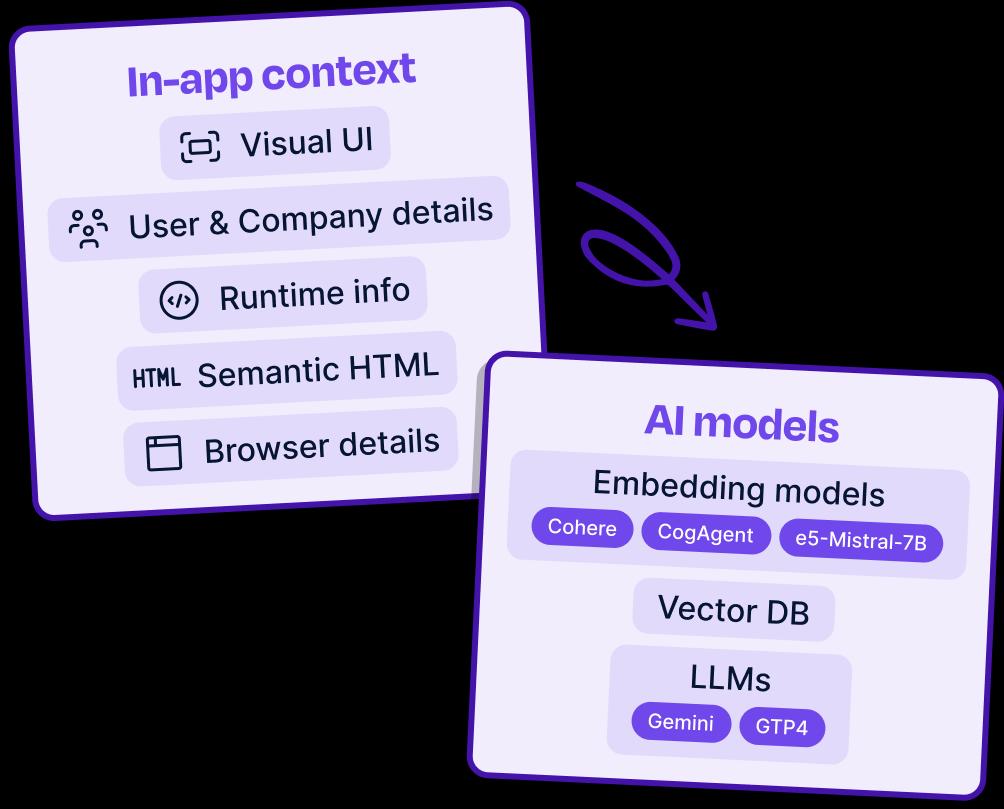
Gathering relevant context for in-app assistance
The interaction models suggested above in Exploring alternate models require multiple, overlapping contexts. We can break these contexts down into two broad categories: static and dynamic.
Static contexts are fixed per app and can be provided at build-time. This static context is often in the form of documentation and other help and support sources related to your app — for example, in Dopt, our static context would include docs.dopt.com and blog.dopt.com. Likewise, navigation, actions, APIs and their related metadata (i.e. descriptions, parameters, API schemas, etc.) can also be configured as static context, since they’re also available at build time.
We could stop building with just static context and produce a functional in-app chatbot. The input to this chatbot would be a string, and a user could ask questions like, “how do I invite a new user to my company workspace?” The chatbot would then search over sources and actions using Retrieval Augmented Generation and respond with generated help text and relevant actions.
This modality suffers from the same problems we encountered earlier in Why not embedded chatbots: first, creating the right prompts to ask questions to chatbots is just plain difficult; second, even with the right prompts, the chatbot won’t have access to the in-app context necessary to retrieve the most relevant sources and actions and generate a quality response.
We can solve both of these problems through the use of dynamic context. Dynamic contexts are those that we can collect within an app at runtime — they differ per user and session and are tied to the things a user is seeing and interacting with.
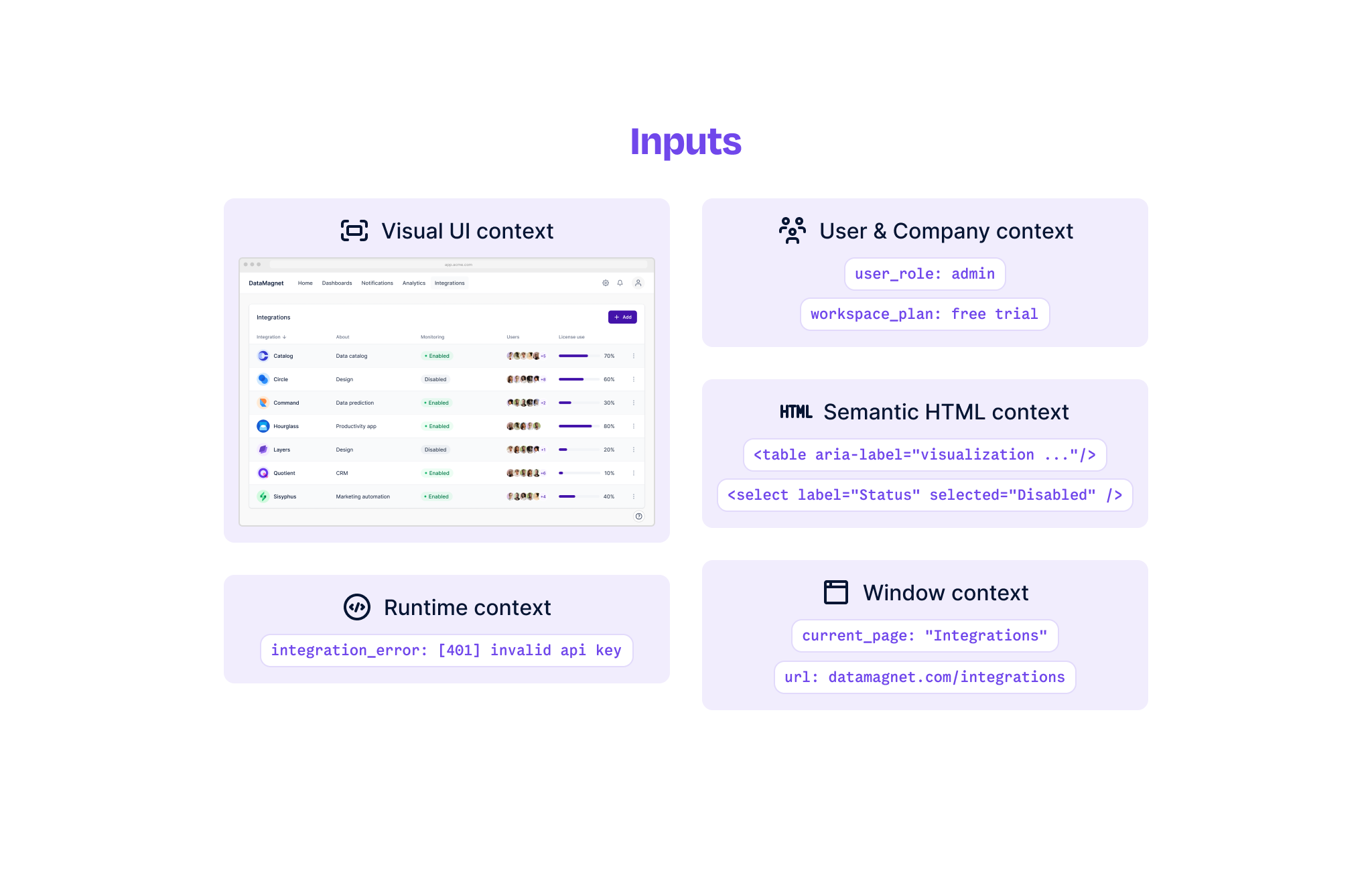
When we collect dynamic in-app contexts, we need to prioritize three key factors: latency, density, and informativeness. We want to make sure that dynamic contexts can be gathered quickly, that they’re compact enough to process and send over-the-wire, and that they capture independently valuable information.
From these criteria, the following contexts stand out as necessary for building an in-app assistant:
- User and company context — at Dopt, we support identifying user and company level properties like a user’s role and their company’s plan. By including this context, we can retrieve the most relevant sources and actions for a user and ensure that our answers are grounded in what they can and cannot do.
- Runtime context, like errors and view states — these are custom contexts where the schema is specified at build time and the value at runtime so that parameterized values can be injected. This context is useful when augmenting an assistant with app state like whether a user is encountering an error.
- Window context — the URL and title of the page within the app that the user is currently viewing. This context is useful for retrieving sources and actions that are relevant to their current page.
- Semantic HTML context — when a user interacts with an element in the DOM, context can be taken directly from that element and its relatives (its ancestors, descendants, and siblings). From the element and its relatives, we grab three types of attributes: descriptive, for example
innerText; interactive, for example an anchor’shrefor an input’svalue; semantic, for exampleroleandlabeloraria-*attributes. Coupled with models trained on HTML, this context can ground a system by specifying what elements a user is interacting with and how they’re performing their interactions. - Visual UI context — since we’re operating in-app, we can directly capture screenshots of what the user is looking at and the elements they’re interacting with. This context serves multiple purposes: first, when other forms of context are incomplete or inaccurate, this context can help ground a user’s questions in sources and actions that are relevant to what they’re viewing; second, jointly embedding visual context with semantic HTML context can enable a deeper understanding of a user’s interactions.
Grounding AI systems by leveraging multiple contexts
Ultimately, our goal is to build an AI system which does the following:
- indexes sources, actions, and other static context
- retrieves relevant sources and actions given users’ queries and dynamic in-app contexts like visual images, semantic HTML, runtime information, and user and company attributes
- uses sources and actions as well as users’ queries and context as grounding for a multimodal LLM to generate meaningful responses to augment in-app experiences
Retrieval
When building a standard RAG system, we first need determine which sources and actions (and other pre-defined static context) are relevant given a user’s question. However, what if a user hasn’t asked a question, but we still want to proactively retrieve the most relevant sources and actions for the page they’re viewing. Alternately, what if a user asks an incomplete question, like “how do I navigate to settings from this page?”
To satisfy all of these potential entry points, we need to build a retrieval system that supports all the different combinations of explicit user query and gathered in-app contexts.
We start by processing static contexts like sources and actions through multiple embeddings models. Whenever sources are added, sources crawled, or actions updated, we’ll run them (and their metadata, like a document’s title or an action’s description) through our models and store the embeddings for future consumption (possibly in a vector DB, but we’ve found pgvector works just fine for moderate volumes).
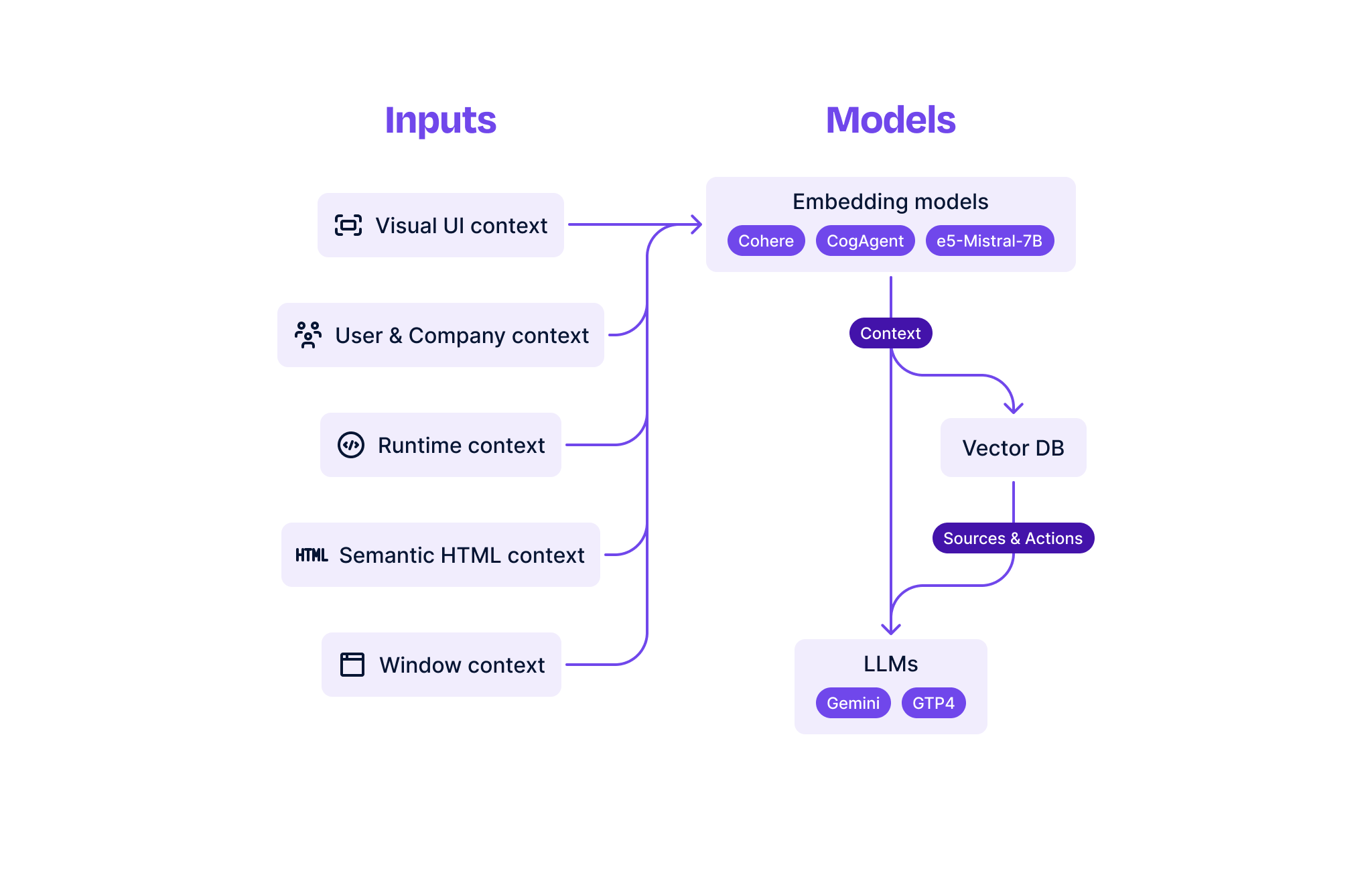
These are a rough collection embedding models that we’ve found to be particularly useful for the in-app contexts outlined above:
- Cohere’s general purpose embeddings —
embed-english-v3.0is a natural language workhorse — we can embed sources and actions with it for retrieval with a user’s raw, unprocessed queries. - Microsoft’s Mistral-7B LLM-derived embeddings —
e5-mistral-7b-instructis a Mistral-7B-instruct derived embedding model. Trained on synthetic data pairs from GPT-4, the model maximizes Mistral-7B-instruct’s instruction fine-tuning with retrieval learned from GPT-4’s synthetic pairings. We can engineer specific instructions for text-based retrieval of sources and actions on user and company properties as well as page and HTML contexts. - THUDM’s CogAgent VLM-derived embeddings —
cogagent-vqais a single-turn visual-question answering vision language model (VLM). The model uses a Llama-2-7B text model augmented with 11B visual parameters and achieves state of the art performance on web GUI tasks. We can extend the model to output meaningful multimodal embeddings and use it for UI screenshot-based retrieval of sources and actions.
Then, when we receive a request with a query and / or in-app contexts, we also embed those with the same models. As outlined above, each piece of the request (the query, the user and company context, the visual UI context, etc.) is embedded in a specific way depending on the information it contains. For example, a screenshot can only be embedded by a multimodal model; likewise, a semantic HTML extract needs to be processed with either a code fine-tuned model or a larger, LLM-derived model. Some contexts like user and company properties or runtime errors blur the line, so we might embed them using two different models.
After this step, we go from a request to a list of embeddings. We can take each embedding and run a nearest-neighbor search against the stored sources and actions to retrieve the most relevant sources and actions for that embedding. If we do this for each embedding and then take the union of the sources and actions, we’re left with a set of sources and actions each of which should have 1 or more similarity scores to each of the embeddings. There are many different ways to order this set, but a modified, weighted rank fusion works pretty well.
/** * Start with a list where each element is an list of embedding scores. * Some elements in the list may be null if that specific sources or action * failed to match with a query and / or in-app context. This may be the case * with either limited or approximate nearest-neighbor searches. */const records: Array<Array<number | null>>;
/** * A function which finds the percentile of an individual record's similarity score * in a population of similarity scored. If the individual record's value is null, * this function returns 1.0 (that is, this record is the most dissimilar record). * Lower percentiles are more similar and higher percentiles less. */const percentile: (individual: number | null, population: Array<number | null>) => number;
/** * A function which finds the weighted harmonic means of its inputs. * Its inputs are an Array of number tuples where the first number * is the value and the second number is the weight. */function weightedHarmonicMean(...inputs: Array<[number, number]>): number { let sum = 0; let weights = 0;
for (const [input, weight] of inputs) { sum += weight / input; weights += weight; }
return weights / sum;}
/** * `weights` are an array of numbers with the same length * as the total number of embeddings. These are hyperparameters * which convey how much each embedding should be weighted in the final * rank fusion. For example, we might believe that images convey * more information than HTML and so the image embedding should have * a higher weight. */const weights: number[];
/** * This final result, `fused` contains each record sorted by * its modified mean reciprocal rank. The first record (source or action) * is the most relevant and the last is the least relevant. */const fused: number[] = records.map((record) => { /** * Compute the weighted percentiles for each of the similarity scores. * `scores` refers to an array of scores for that specific embedding. */ const weightedPercentiles = record.map((score, index) => { return [ percentile(score, scores), weights[index] ]; }) as Array<[number, number]>;
return weightedHarmonicMean(...weightedPercentiles);}).sort((a, b) => a - b);An important thing to consider when using the weighted fusion approach outlined above is the importance of the weights hyperparameters.
One way you could do this is by sitting next to someone and fiddling with the hyperparameters while they thumbs-up or thumbs-down your results (we did this ourselves when prototyping!).
A more robust way might be to ask raters to evaluate retrieved results across the hyperparameter grid and then create a linear model on top of those ratings to interpolate the best weights values.
We much prefer this weighted linear model approach to other reranking approaches like using a transformer-based cross-encoder for reranking. Because of the diversity of contexts and queries we consider, a cross-encoder would have to be fairly large and quite slow in order to encapsulate all the possible inputs against which we want to rank our retrieved results. We find our weighted linear model approach, once fine-tuned, provides just as much flexibility with the benefit of greatly improved speed.
Generation
Once we’ve retrieved a set of results that we feel comfortable with, the next step is to generate a meaningful answer. A simple approach might be to just dump everything into a prompt and hope the vision-LLM returns a meaningful result. Through some quick experiments with multimodal foundation models like GPT-4V and Gemini, we can quickly discover that this isn’t the case.
Instead, we can use a combination of chain-of-thought derivatives and context-specific grounding to coax these foundation models into producing intelligible results.
Chain-of-Note suggests that we can improve RAG by producing piecewise notes first and then a subsequent answer to get a better result. The authors offer the following prompt for summarizing Wikipedia:
Task Description:1. Read the given question and five Wikipedia passages to gather relevant information.2. Write reading notes summarizing the key points from these passages.3. Discuss the relevance of the given question and Wikipedia passages.4. If some passages are relevant to the given question, provide a brief answer based on the passages.5. If no passage is relevant, directly provide answer without considering the passages.We follow this general template, but instead pass in sources and actions. One of the main highlights of Chain-of-Note, covered by steps 4 and 5, is that it avoids explicitly instructing an LLM to produce a canned answer like “I do not have enough information” in negative cases. Instead, it allows the LLM to decide on what pieces of information from sources and context are relevant. This enables the LLM to more freely produce an answer based on any of the additional contexts provided to it.
We introduce the additional contexts to the LLM in the form of follow-up messages. We can explain each additional piece of context like so:
User: Here is an image of {url} where the user is interacting with {element.innerText}.User: {base64 image}Assistant: OK
User: Here is the HTML of {element.innerText} that the user is interacting with.User: {HTML}Assistant: OKSeeAct provides a deeper exploration of how to ground GPT-4V with web and HTML context for accurate agent-like answers. We found their explorations particularly helpful when iterating and evaluating custom prompts for combinations of context.
Once all contexts are passed to the LLM, we can then ask it to answer a question. If the user has entered a question, we pass that question directly to the LLM. Alternately, depending on the specific interaction model of our in-app assistant, we can create an instruction based on the available contexts.
User: Here is my question: “{query}”
User: Provide a brief explanation of what the {element.innerText} {element.type} does.
User: Provide a brief explanation and next steps for how the user should respond to {runtime.error}.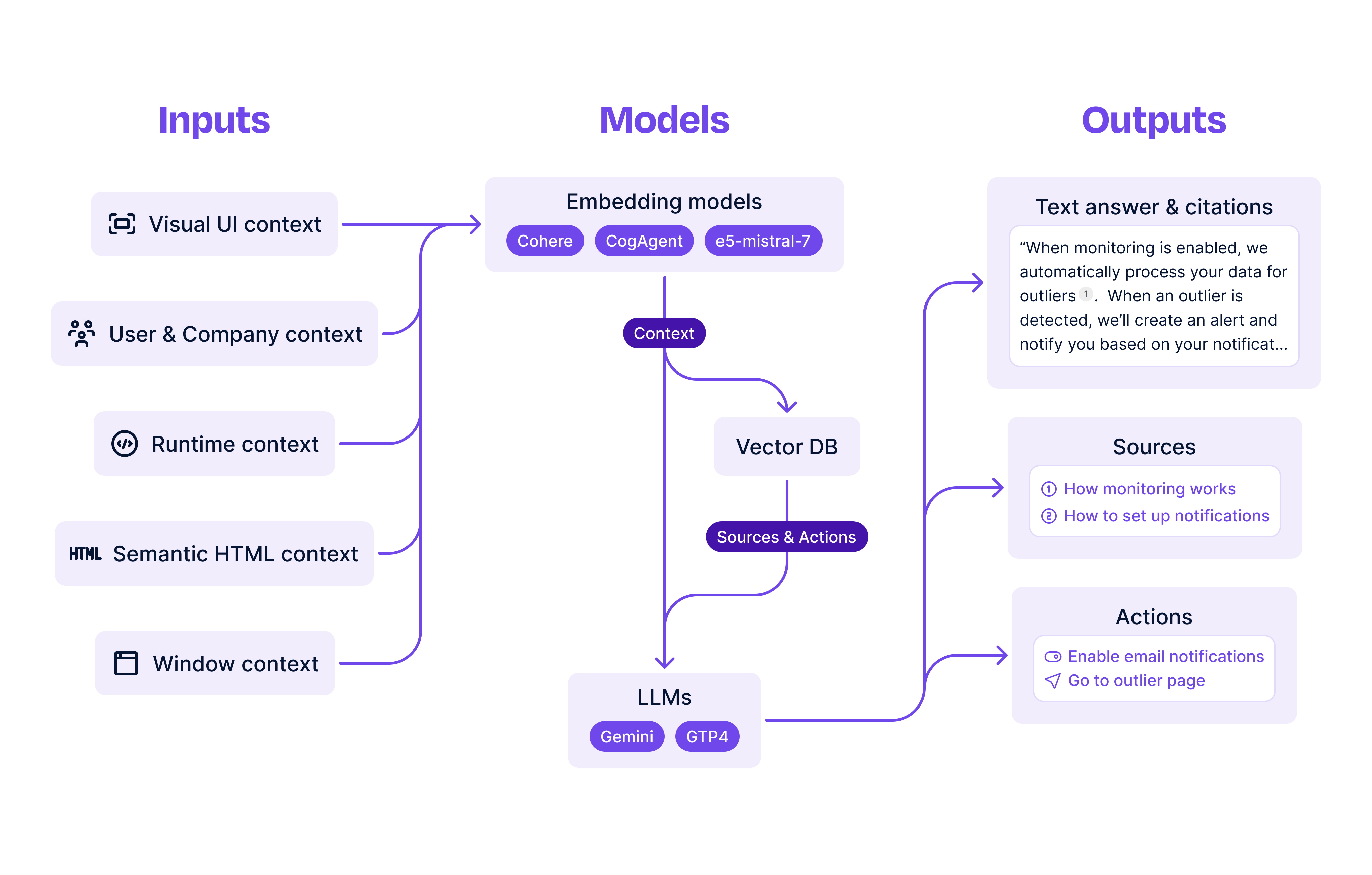
As with customizing embeddings and tuning weights during retrieval, engineering a system of prompts for multiple contexts and queries is a highly iterative process that requires care and attention as LLMs and contexts evolve. We’ve found that we can go a long way by continuously testing the model and seeing how results match expectations. Likewise, we’ve found that refinement along these axes is much closer to A / B testing than model optimization since the outcomes being optimized are heavily user dependent.
Building magical experiences
We’re finally to the magical experiences part! We’re ready to surface our generated answers and their underlying sources and actions in our in-app assistant.
At Dopt, we’re actively building a few different magical experiences for embedded AI assistants. We’ve found that experiences all share two important requirements: they need to be fast, and they need to be useful.
First, speed. Much of what we’ve architected above includes considerations of speed: we optimize our in-app contexts so that they’re fast to collect in the browser; we rely heavily on embeddings which are relatively fast to compute; we perform ranking of our retrieved sources and actions via a simple linear model; and last, we minimize the footprint of our most expensive step, the call to a multimodal foundation model, by only performing it once. From the perspective of a user, we can return relevant sources and actions within a few hundred milliseconds after their interaction; we can then start streaming an answer to them within a second. For AI experiences, these speeds are pretty magical.
Then, usefulness. This part is a lot trickier, but here are a few things we’ve learned. First, foundation models, while wonderful, can easily be flooded with irrelevant information. Through our weighted ranking system, we try to filter down sources and actions and context aggressively so that we can minimize the amount of irrelevant information the LLM has to parse during generation. Sometimes, this means that recall is sacrificed for precision. Second, even with relevant sources and actions and in-app context, answers need to be succinct and actionable. Fortunately (or unfortunately), the main lever here is how we engineer prompts, a process that is pretty chaotic and largely driven by trial-and-error.
See what we’re up to!
At Dopt, we believe that embedded in-app assistants are the future of AI experiences. Much of what we’ve written here is directly based on our experiences prototyping and shipping these assistants and the systems that power them.
If you’re interested in learning more about what we’re building, visit dopt.com/ai.
Dive deeper
- Boo Chatbots: Why Chatbots Are Not the Future
- Understanding HTML with Large Language Models
- Multimodal Web Navigation with Instruction-Finetuned Foundation Models
- Improving Text Embeddings with Large Language Models
- CogAgent: A Visual Language Model for GUI Agents
- Scaling Sentence Embeddings with Large Language Models
- Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models
- SeeAct: GPT-4V(ision) is a Generalist Web Agent, if Grounded