
The problems you’ll face building product onboarding & education in-house
- December 21, 2023
- 11 min read
Everyone with a self-serve product wants to build an amazing user journey—onboarding, education, engagement, and upsell experiences that show the right thing to the right user at exactly the right moment in time.
Experiences that help users get successful without spamming them or getting in their way.
That aren’t bolted on afterthoughts.
That do all of the above while still driving results for the business.
We started Dopt because no-code product adoption tools are too inflexible and brittle to get you there. We had disqualified them to build in-house, and the companies we spoke to (and now work with!), like Superhuman, Productboard, and Attio, did too.
What wasn’t immediately apparent to us the first time we built onboarding is how fiendishly difficult it would be to do.
We’re not alone; it’s a common objection we get. A lot of companies ask us, “How hard can it be?” And in a small sense, they’re not wrong. Adding a simple tooltip tour or checklist to your app isn’t hard. You can grab an off-the-shelf open-source library and do it in a few hours.
But the cold, hard reality is that a simple tooltip tour won’t work well.
Building a great self-serve user product takes so much more than a single tour; you’ll need to construct and orchestrate your users’ journeys thoughtfully. Journeys that won’t (and shouldn’t) all look the same for every user.
And, most importantly, you won't get it right at first. You’ll need to try, iterate, and learn what works for your product.
I can’t underscore this point enough: without bringing a mindset of iteration and learning to the table, you will fail.
So, with that in mind, what’s so hard about building in-product onboarding and education yourself?
- Targeting the right users requires data often inaccessible in the product, so most companies end up with irrelevant, one-size-fits-all experiences that don’t perform well
- Managing user journey state to keep track of who’s seen what requires costly migrations if you want to avoid spamming users with repeated experiences
- You need to react to changing user data & behavior as it occurs to create contextual experiences, and doing so requires complicated real-time infrastructure
- Non-developers can’t see what users experience and get bottlenecked on changes, making collaboration difficult, slowing iteration & learning, and undercutting results
- Understanding what’s working requires painstaking instrumentation and analytics work that’s easy to mess up, and any missteps mean you miss out on opportunities to learn
- Knowing what good looks like & where to start is hard, and most teams waste time and learning cycles reinventing the wheel
Let’s dig a bit deeper into each of these.
Targeting the right users requires data often inaccessible in the product
B2B SaaS products are complex, serving multiple users and use cases. What’s most relevant for an admin who just signed up to set up a workspace won’t be relevant for a user who just signed up to view something shared with them, or for a power user who’s coming back into the product for the hundredth time.
The term “personalization” gets thrown around a lot, and many view it as a pie-in-the-sky “maybe we’ll be there one day” thing.
But showing the right users the right experience is a day-one problem for every SaaS product.
It requires you to understand where a user is along their journey—what have they done? What should they do next? What’s not relevant yet?
Without contending with these questions, you’ll quickly get to a place where there are so many things vying for users’ attention that they start stacking up and eroding trust in your product’s quality.
It’s a hard enough problem that most companies that build in-house ignore it and show their users one-size-fits-all experiences that aren’t nearly as effective.
Why is it hard to get this right?
The information you want to target on lives across multiple places and is inaccessible when building in product.
Let’s say I want to announce a new feature that’s only relevant to admins. I’m going to have my account management team communicate this directly with my larger customers, but I want to get the word out to my smaller customers in-product. I don’t want to show it to customers in a trial so they stay focused on getting set up and activated.
So, I need a way to target:
- admins
- in paid workspaces
- at companies with less than 1000 employees
- who’s workspaces have already completed key setup steps and have activated
Some of this (like a user’s role or a company’s plan) I might have handy in my app database. Some of it (like company size) isn’t there but might exist in my CRM. Some of it (like whether a workspace has activated) might be more complex, based on a user or workspaces’ product behaviors, and exist only in my product analytics tool or data warehouse (that is, if my definition of it hasn’t changed recently!)
All of the data outside my application database is inaccessible when building product experiences.
I can add it there, but now I’m in the business of building data pipelines, ensuring the data is being updated regularly, updating it as properties evolve or definitions change, and fixing any breakages.
And that’s just the data.
Putting the logic for targeting in code is also brittle.
Whenever the data or definitions of my target segments change, I’m on the hook for finding and updating all dependent code. If I fail to do this, I risk breakages that lead to users getting spammed or missing experiences that could have helped them succeed.
Managing journey state to keep track of who’s seen what is complicated
The best products respect their users’ time and attention, and nothing erodes goodwill quite like being shown an irrelevant experience again and again. We’ve all used products that have spammed us with a modal we’ve already dismissed. Why? Getting it right takes effort.
Let’s say you want to build an onboarding checklist. You’ll need a way to keep track of user state, or what each user has done (e.g., alon@dopt.com has completed the first two out of three steps).
You’ll need to store that information somewhere and, more importantly, make sure you migrate it each time you make a change or iterate on the experience.
Storing user journey state isn’t as simple as you might expect.
There are some quick hacks you’ll see, like putting this user state in a cookie or local storage, but those fall down because they’re not durable; each time a user uses a different device, uses an incognito window, or clears their cache, they’ll see everything all over again.
So, you’ll end up storing this user state in your database.
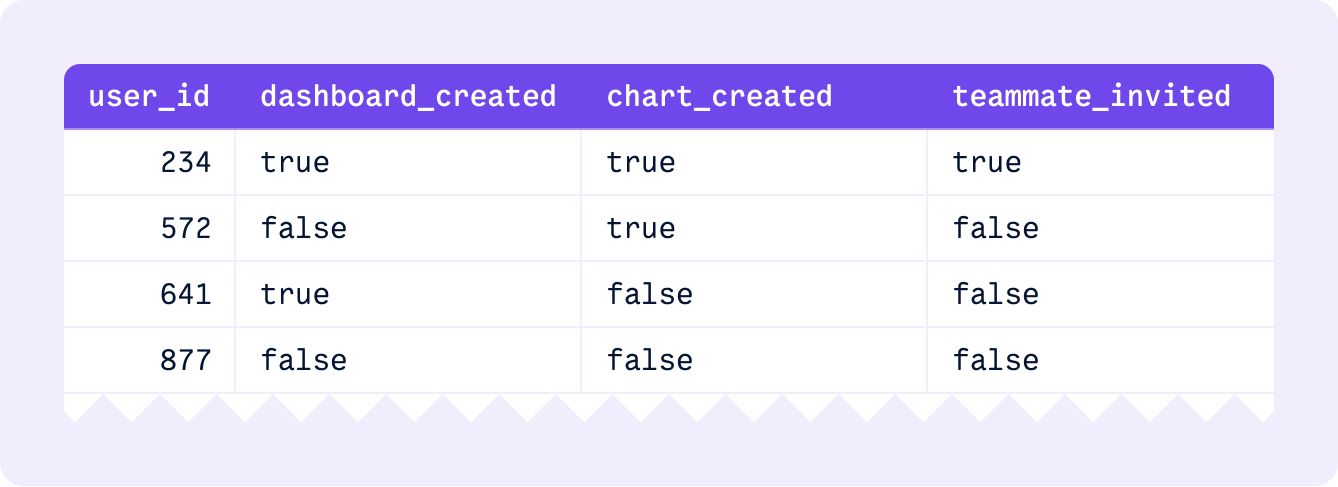
But there’s a smell to this. This state is best thought of as “user journey state”. It tracks where a user is along their journey and whether they’ve seen a given experience in the app. But those experiences and the application context they live in both change frequently. And to further complicate things…
The journey state is never only at the user level.
Often, you’ll want to track whether anyone at a company has completed some key action, like setting up a workspace-level integration.

Contrast this with properties of users (e.g., their role), workspaces (e.g., a plan or trial status), or objects that’ve been created in your app (e.g., a notebook, doc, or dashboard). These are core to modeling your application, and this data's structure changes much less frequently.
Migrating journey state is so hard that you won’t iterate as often as you should.
Let’s assume you now want to change that getting started checklist. This is where the wheels start really coming off the bus.
In your database, you’d add a column that represents that new step being complete for some users, easy enough.
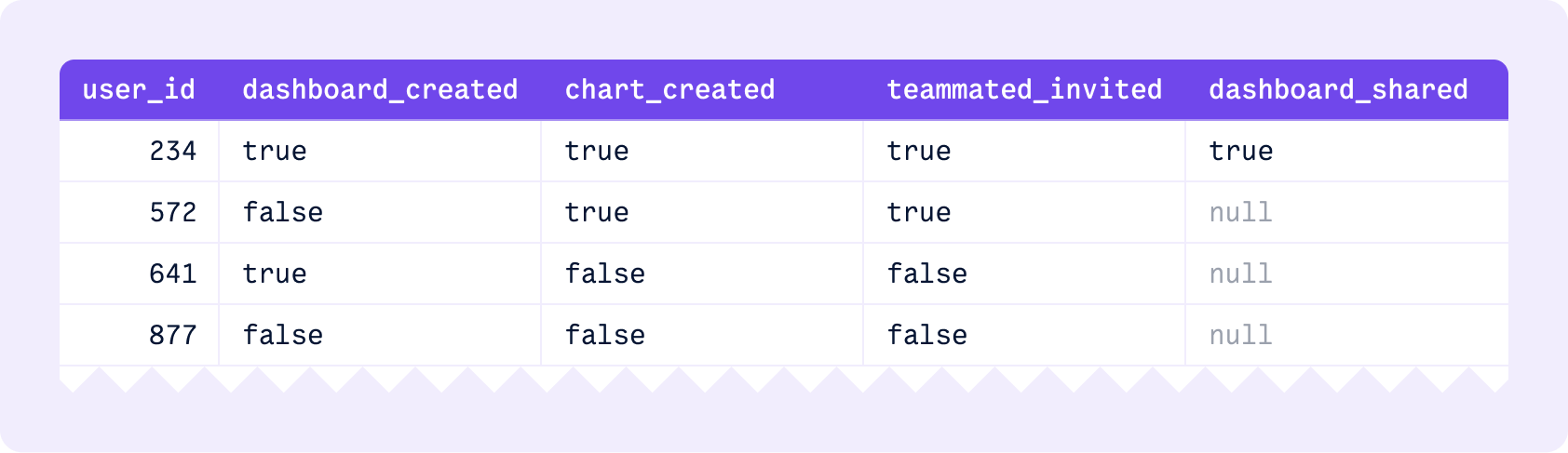
You now need to figure out what to do with your existing users! Some may be partway through your current checklist, and some may have finished it long ago.
You’re now in the territory of writing data migrations for each and every change.
- Maybe you want to backfill all users who completed the old checklist as ‘complete’, so they don’t see the new, nearly identical checklist again.
- Or maybe you want to carry users partway through over, interleaving new checklist steps into what they’ve already completed.
- There are also times you’ll want to knock everyone out of an experience partway through, like when the product context has changed enough that a partially completed tour no longer makes sense.
- And other times you’ll want to reset state for everyone, like if you’re reusing a card in the side navigation for a new feature announcement.
No matter what the circumstances you’ll find yourself grappling with questions each time you make a change, each of these is a tricky data migration that adds cost to every iteration. Once again, you’ll be trading effort off against quality, and skipping this step means spamming users or dropping them out of crucial setup flows.
And this is just for the simple case where each state can be modeled independently.
Most flows are dependent, e.g., a tour, where a user should only see step two if they’ve completed step one, or an announcement a user should only see once they’ve completed their getting started checklist.
You’ll need to track these dependencies to orchestrate flows and avoid multiple conflicting experiences.
Modeling them in a database is so complicated that you’ll likely sidestep it and hardcode those relationships in code, introducing brittleness that’s hard to reason about, change, and is liable to break as you iterate or your product evolves.
If you want to read more about the challenges you’ll face managing journey state, our engineer Karthik wrote up a deep dive into the challenges he faced when he implemented and iterated on a set of tours in a past life.
Reacting to changes as they happen is crucial, yet very hard to build
Effective onboarding, education, adoption, and upsell experiences are contextual. They take into account information you know about your users, their workspaces, and where they are along their journeys.
We’ve established that you will have multiple flows that will evolve over time, each targeting different subsets of your users. They also depend on each other and on what you know about a user and their workspace.
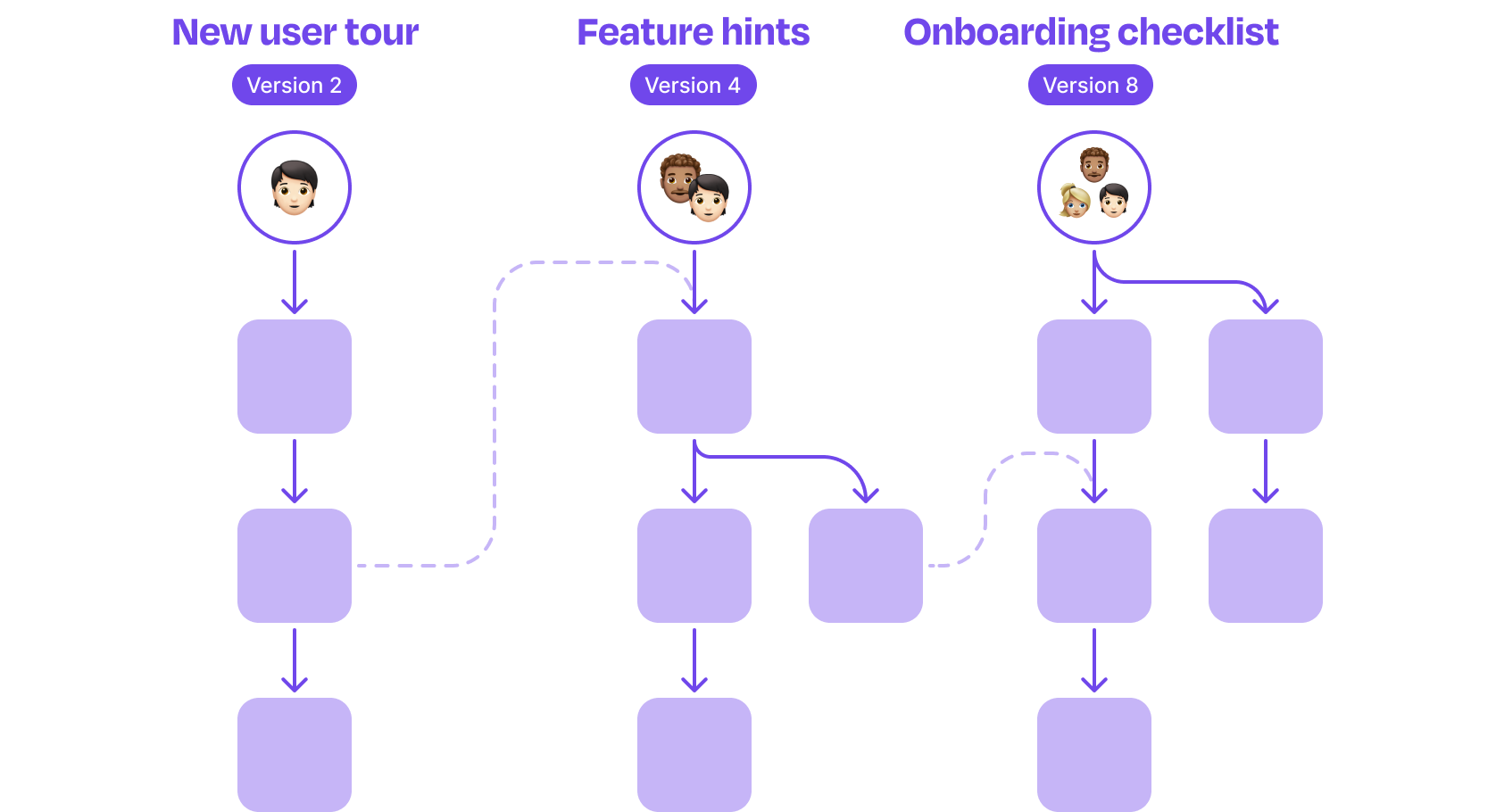
Now something changes.
- A workspace upgrades from free to paid, or a user’s role changes from viewer to admin
- A user publishes their first report, a different user sets up a key integration for the workspace, or the system finishes running an import job
- A workspace hits day thirteen of a fourteen-day trial
All of a sudden, what a user sees needs to change.
To be contextual, the experiences you show users need to react to those changes in real-time.
- Maybe embedded upsell prompts should disappear, or education about new features they now have access to should appear
- Or getting started checklist steps should be completed, regardless of how an action was completed
- Or a message should appear letting a user know they have one day left in their trial
Handling these changes requires architecting and building a complex reactive system.
You need:
- a way to find all dependencies each time something changes, e.g., “if a workspace upgrades, what journey states need to be updated?”
- a way to push these updates from the server to the client so experiences respond to those changes (like an upsell prompt disappearing)
Both are hard technical problems. Pubsub systems that support real-time interactions are hard to build, and you’ll have to deal with many issues shipping sockets in production (reconnection behavior, sticky sessions, etc…).
You can skip these steps, but your experiences will quickly fall out of sync. Users will see feature education that’s wrong given the plan they’re on; they’ll run into errors trying to set up or enable things that someone already has, see upsells when they’ve already paid, run out of time in their trial before they’ve had a chance to finish their evaluation.
What you show users is no longer contextual, their overall experience has degraded, and they’re less likely to succeed.
Non-developers can’t see what users experience and get bottlenecked
Building great growth experiences takes a village, but if you build your own experiences in-house, developers become a bottleneck for each and every change, no matter how big or small.
Product managers, designers, marketers, customer success, and sales want to reach users through the product but get blocked.
The quick iterations that are the lifeblood of a successful self-serve motion slow to a crawl.
Want to update the copy in your welcome modal or update a documentation link in your getting started checklist? Code push.
Updating segmentation logic so your trial-end banner stops showing up for the wrong users? Code push.
Want to publish last week’s feature releases as an in-app announcement? You have to keep track of who’s already seen it. A schema update and a more complicated code push.
Changing a checklist, adding a tour step, adding new contextual tips? We’re back in data migration territory.
And because the source of truth lives in code, non-developers don’t know what users see in the product.
This bottleneck becomes such a big issue that many companies reach for no-code tools (which come with their own deep set of compromises). It’s also why companies like Dropbox, Figma, Airtable, and Asana spend millions building their own internal growth platforms to make it easier for non-developers to self-serve when defining targeting, content, and logic.
Understanding what’s working requires painstaking work
Whatever you build, you won’t get it right the first time. You’ll need to try things to learn about what works and where you have opportunities to improve. But building in a way that makes learning possible takes work.
Instrumenting events is time-consuming and lossy.
You’ll need to be diligent about capturing data about what users see and do. You’ll need to make sure you’re not missing events and capturing sufficient context. Things like what iteration you’re on, what your users’ role or plan looked like, what content you surfaced to them, and what the broader experience looked like at that moment time.
Screw this up, and you’ll lose data and have an incomplete picture.
You’ll also need to make sure that data gets sent to the rest of your tools. But now you have another problem.
Analytics tools are general purpose, and getting good insights is excruciating.
User journeys are complex and non-linear. They branch, meander, backtrack, and sometimes even cycle. But you won’t be able to easily visualize any of this.
Instead, you’ll need to take the imperfectly captured mess of behavioral data representing these interdependent and regularly changing flows and reconstruct them as linear funnels. Funnels, plural. Because you’re going to have a lot of these.
You should be doing all of this for any of the product work you ship. But the regularly evolving nature of onboarding and education experiences, their cross-cutting nature, and the sheer number you’ll end up building means the surface area you’ll need to do this for will explode.
Determining what good looks like & where to start is hard
Even if you’ve been at this for a while, you’ll have questions about what great onboarding and education look like for your product. What patterns are effective? What modalities will work for my interaction model? Every product is unique, with unique users and unique aha moments.
Looking at others can help you understand what patterns might work for them, but you’ll never get the full picture. Are you looking at a failed experiment? Or something that’s knocking it out of the park? How applicable is any success they’re finding to your specific context?
The only way to answer these is to ship fast and iterate often.
You’ll want to reach for established patterns as starting points; they’ll help you avoid wasting learning cycles reinventing the wheel. But you’ll need to try different things to determine what works best for you.
You’ll be designing and building a lot of UI along the way. That means additional design and development time spent on each iteration. You’ll move slower, learn slower, and grow slower.
So why build?
I’ve just made a pretty emphatic case for why building in-house is harder than expected. So why do people still do it?
A few reasons:
- it’s easy enough to ship something simple
- the historical alternatives are brittle and inflexible
- you care about quality and want the control to build something that fits your product
We’ve already discussed why simple experiences won’t get you to the promised land, and why going beyond them gets hard quickly.
The no-code tools on the market exist as a category because people that started building ended up facing all of these hard problems. But in doing so, they box you into brittle, cookie-cutter experiences that don’t fit your product and don’t work. Their compromises run so deep that you can’t build a great self-serve journey with them. Don’t believe me? Look at the companies with the best self-serve products—you won’t find Linear, Airtable, or Notion using them.
Building allows you to blur the line between your product and the experiences aimed at educating your users and getting them successful. You can let users take real product actions, like configuring a new feature from within an announcement. You can use your components or build bespoke experiences, seamlessly blending education into your product’s core interaction model.
But most teams end up with half-baked experiences that don’t work. They ship a simple checklist or tooltip tour and quickly find themselves grappling with problems requiring a ton of engineering time and effort at the expense of core value they could build into their products.
Dopt can help you build great onboarding & education, quickly
We built Dopt because we saw teams struggling to build great self-serve journeys. Like us, many had disqualified no-code tools.
Dopt is different. We’re developer-first. We solve the hard problems for you so you can move fast without giving up the flexibility required to build great experiences across your entire user journey.
- We’ll connect to all of your customer data to make it easy to target
- We’ll store and migrate user journey state for you
- We’ll propagate updates and changes to your users in real-time
- We’ll give you a platform that allows developers and non-developers to collaboratively define, build, and iterate faster
- We’ll help you easily understand what’s working, highlight where there are opportunities for improvement, and send all of that data downstream to your analytics tool of choice
- We’ll give you a set of out-of-the-box components for common patterns that you can use to hit the ground running in minutes
- But we’ll also make it easy to buy out and use us headlessly—build with your own components or build with a third-party component library; you’ll have no limits on what you can build (you can even build onboarding into a CLI with Dopt)
We’re built for developers, sweating the details on the small but important stuff that makes developing with Dopt a joy: versions, environments, framework-specific SDKs & clients, tools for local development, and excellent documentation.
But we’re also built for non-developers, helping them understand what’s working and giving them the tools they need to self-serve.
Trying to improve your self-serve user journey? Sign up and start building today. You’ll have the flexibility to get creative, try more, and be proud of what you ship.