State machines and their influence on our SDKs
- February 2, 2023
- 8 min read
Today, we’re pumped to talk about the 1.0 release of our SDKs
The 1.0 release represents a significant milestone in terms of stability and our confidence in the core solution. It includes
- A reorganization of the block and flow states we expose
- Methods for accessing states and commands for changing states
- A new representation of the block and flow entities that we return to you
With this foundation, we are confident that we can continue to build out the vision of Dopt without significant breaking changes.
Up until 1.0, every single publication was potentially breaking. While we tried to minimize breaking changes, we had quite a bit to learn about how customers would use our SDKs. Moving forwards, all releases of our SDKs will follow the full semantics of the semver standard.
The pre-1.0 SDKs were purposefully primitive. They exposed blocks only (no flow concept). The thinking was this: if the SDKs focused on consumption and transition of Block state and Dopt focused on the implications of those block state transitions on the flow - we have a nice/powerful separation of concerns.
There are some real trade-offs to consider with that approach. As we got customer feedback and considered how to incorporate it—it was clear that we need to offer more; in particular, we needed to expose flow concepts to support typical use cases (e.g., a state representing a user starting or prematurely “exiting” a flow).
Above, I mentioned that flows are like state machines. As we ventured towards exposing more of the “machine,” we took a brief detour into prior art and thinking around state machines to inform some of our design. Accordingly, let’s start by talking about state machines.
State machines, statecharts, and how they relate to Dopt
A coworker at my first job as a software engineer once told me that UI programming is just building “shitty little state machines”. For those of us who have made a career out of building UI or even dabbled in it, the sentiment isn’t that far off the mark, nor is the idea of state machines in UI novel. Often these machines exist implicitly in code. Sometimes, but maybe less often than we ought to, we formalize these machines.
When I say state machine, I mean deterministic finite automata (DFA) in particular—like the one below.
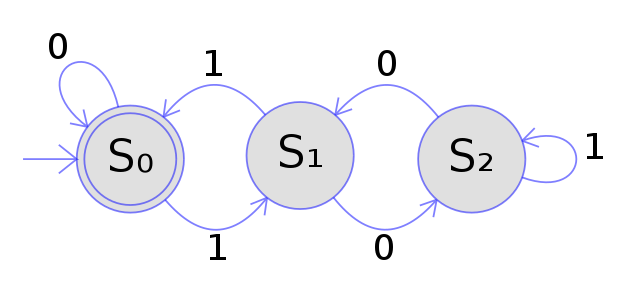
These state machines seem most applicable to UI programming and Dopt. They are deterministic because for each input, the next state is known, finite because the number of states is finite, and automata because automata theory is the branch of computer science that deals with the logic of computation with respect to simple machines, and the various problem that can be solved using them.
Truthfully, state machines in typical software development feel a bit forced, i.e., they tend to either be too rigid (read state explosion) or formal (read academic and esoteric) to solve typical real-world problems in code. That being said, there has been quite a bit of thought about how state machines (and their theory) can be extended to better serve real-world usage—in particular David Harel’s 1987 paper Statecharts: A Visual Formalism for Complex Systems. Statecharts are a formalism for modeling stateful, reactive systems. Many of the extensions put forth in that paper had a direct influence on our current solution. We're not the only ones either; Xstate.js is essentially statecharts as a generic open-source tool.
You’ll note that I said statecharts were a “formalism for modeling”. It’s worth calling out that state machines can serve two purposes, they are effective tools for visually modeling complex systems, and they can be executed, i.e., they can exist and be utilized at runtime. Let’s create a simplified and shared language for these two concepts or moments:
- Design-time Machines
- Run-time Machines
Dopt and tools like Xstate.js, exist across these two moments; that is they allow you to collaboratively design/model a machine and expose it for usage in code. Tools that bridge these two moments exist for a reason. Design-time machines allow various stakeholders to have visibility and input into the model. Run-time machines let developers use the result of that collaboration in code to solve real problems.
Earlier, I indicated that using state machines in code was not very common. While that is probably true, I’d argue that the widespread adoption of React has changed the state machine game in frontend software development. React has brought aspects of Functional Reactive Programming to the web, in particular, one-way state transitions, which naturally promote a separation between state and presentation. This has created an excellent opportunity for libraries (e.g., XState, Zagjs, React Stately) and businesses (stately.ai) to capitalize on the need for better state management solutions. Solutions that, unsurprisingly, incorporate concepts from state machines or statecharts.
Thinking back on my experience developing software, some of the more interesting applications of the concepts explored above have come about when the state of the machine, albeit an implicit machine, required persistence. Saying the state of the machine is somewhat misleading—I mean the state of a machine for some entity, e.g., a user or some organizational concept like a workspace. I’ve most often encountered machine state persistance in the context of user onboarding but think the problem can be generalized to any situation where requirements read like so:
If a user has seen X they shouldn’t see it again, they should see Y, and if they’ve seen Y, they shouldn’t see it again; they should see…
This is quite common if you build experiences that meet your user along their journey in your app. Onboarding tours, contextual help for new features, etc. Experiences we come across all the time in tools that do this well (e.g., Slack and Figma) feel both natural and enjoyable.
Dopt marries prior art related to state machines and state charts with modern developer tooling to make building those types of experiences simple and enjoyable.
Design-time Machines and Run-time Machines at Dopt
Dopt provides a visual canvas for collaboratively modeling your design-time machines and APIs/SDKs for accessing run-time machines.
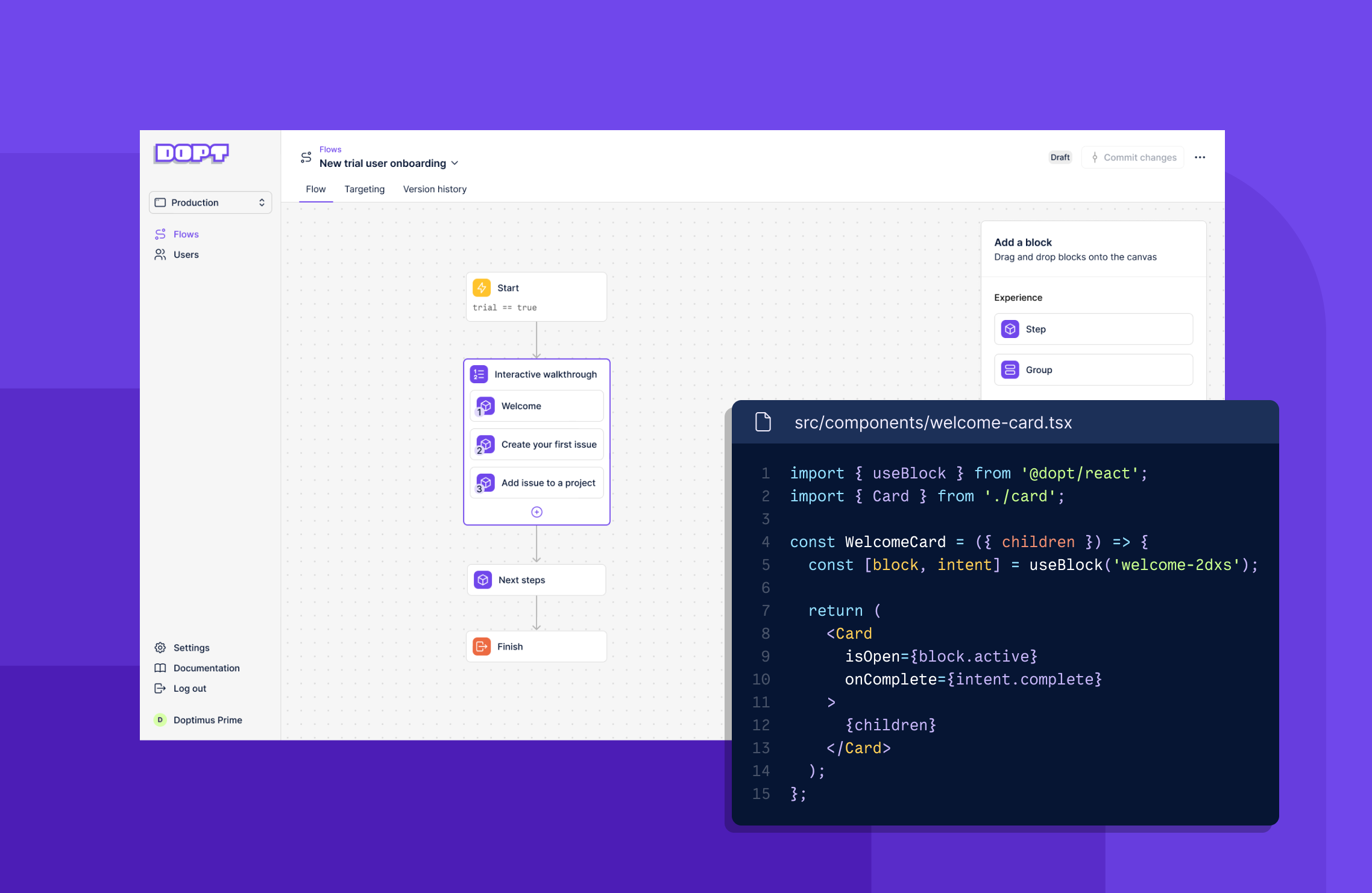
We call our machines Flows. Flows are graphs comprised of Blocks and Paths (edges). At design time, you are presented with a palette of block types to use when modeling your flow. All block types will have two states at runtime.
| Block state | Type |
|---|---|
| active | boolean |
| completed | boolean |
These states are contextual to a user of your product. The active state implies that the user is currently at that block in the flow. The completed state indicates the user has completed this block and transitioned onward in the flow.
When a block is completed, the user transitions along outgoing edges to the next blocks in the flow. The completed block becomes inactive, and the next blocks become active.
Completing a block can happen in one of two ways.
- Dopt completed the block as a side-effect of something else
- The SDK was used to make an API request to complete the block
Not all block types can be controlled by the SDK, and different block types have different rules regarding how they are completed.
| Block type | Available in SDK | Description |
|---|---|---|
| Start | ⛔ | A logical block. Determines which users enter the flow. Completed if the expression you craft evaluates true for the user. Evaluated anytime the SDK initializes and the user has not yet satisfied the condition. |
| Step | ✅ | Our base block. A simple stateful container. Completed via SDK. |
| Finish | ⛔ | A terminal block—reaching this block completes the flow. |
Additionally, flows are stateful. While not part of the palette at design time in Dopt, you are still implicitly designing a flow whose state is a function of its parts, which are themselves stateful. Flows and their states are available for use in the SDK.
| Flow state | Type |
|---|---|
| completed | boolean |
| started | boolean |
| exited | boolean |
For the objects exposed in the SDK, their states are affected by intents—essentially methods that map to an intent-based API. These intents have side effects i.e., they transition block state which transitions flow state. In general, each state (with the exception of active) has a corresponding intent.
Pre-1.0 SDKs and what we learned
In the initial versions of the SDKs, we only exposed blocks to the SDK. The idea was that if the SDKs focused on consumption and transition of Block state and Dopt focused on the implications of those block state transitions - we have a nice/powerful separation of concerns.
At design time, the flow was the primary concern—the Dopt user is modeling their user’s journey. At run-time, since only a subset of blocks is available in the SDK, we can keep the SDK simple and focused i.e. it gives access to blocks and their state and it offers methods for transitioning said state.
There were a few drawbacks to this approach. The primary issue was that we overloaded the block state to include flow-level state and intentions to support common use cases (e.g., state and intentions representing a user starting or prematurely “exiting” a flow). Additionally, by only exposing blocks and their state, we made usage patterns where the state of the app was centralized more cumbersome. Concretely, we assumed that the hook and transitioning state would live close to the experience that state powers—but that’s a strong assumption. Perhaps you already have a state management solution and your state is more centralized or global.
Additionally, we started with a loose assumption that we may only need one block type (the step block) for folks to complete their use cases. Relating this assumption to statecharts—we weren’t entirely sure that hierarchical blocks were necessary.
1.0 SDKs and beyond
Given feedback and learnings we’ve made the following changes in the 1.0.0 release.
- We expose the flow and its states to the SDK
- A reorganization of the block and flow states
- New methods transitioning said states
- A new representation of the block and flow entities that we return to you
Exposing the flow and its associated blocks allows developers to choose how they organize their state in code. They can have a centralized state implementation and subscribe to a state change of blocks (or the flow) through the flow or they can continue to access blocks individually throughout their code.
The choice to expose the flow meant that we had an opportunity to reorganize and simplify the states. Below, you can see how this played out.
| Block state | v0.x.x | v1.x.x |
|---|---|---|
| active | ✅ | ✅ |
| completed | ✅ | ✅ |
| started | ✅ | ⛔ |
| stopped | ✅ | ⛔ |
| exited | ✅ | ⛔ |
| Flow state | v0.x.x | v1.x.x |
|---|---|---|
| completed | ⛔ | ✅ |
| started | ⛔ | ✅ |
| exited | ⛔ | ✅ |
Since each state (with the exception of active) has a corresponding intent, we reorganized and simplified those as well.
| Block intention | v0.x.x | v1.x.x |
|---|---|---|
| complete | ✅ | ✅ |
| start | ✅ | ⛔ |
| stop | ✅ | ⛔ |
| exit | ✅ | ⛔ |
| Flow intention | v0.x.x | v1.x.x |
|---|---|---|
| reset | ✅ | ✅ |
| start | ⛔ | ✅ |
| complete | ⛔ | ✅ |
| exit | ⛔ | ✅ |
You’ll note that we added a reset intent to the flow which doesn’t have a corresponding state. This intent resets all blocks in the flow to their initial state. This is quite useful for supporting experiences where the user has the ability to restart the experience.
The primary mechanism for accessing blocks in the SDK is the useBlock hook we offer. Before the 1.0 release, it’s type definition looked something like this
v0.x.x
interface BlockState { completed: boolean; started: boolean; exited: boolean; stopped: boolean;}
interface BlockIntention { complete: () => void; start: () => void; exit: () => void; stop: () => void;}
const useBlock: (uid: string) => [state: BlockState, intent: BlockIntention]Starting in 1.0 we expose the block entity as opposed to only its state. This should make it easier to work with collections of blocks (e.g. when accessing a flow’s blocks). We expose the block version, which can be helpful in debugging your Dopt usage. Also, the sid is a nod towards an upcoming feature i.e. semantic identifiers for blocks. These are url-safe human-readable identifiers—that way you don’t have to put hashes in your codebase! Additionally, you will see the block state and intention changes manifest here.
v1.x.x
interface Block<T> { readonly kind: "block"; readonly type: T; readonly uid: string; readonly sid: string; readonly version: number; readonly state: { active: boolean; completed: boolean; };}
interface BlockIntention { complete: () => void;}
const useBlock: (uid: Block['uid']) => [block: Block, intent: BlockIntention]We mentioned that we expose the flow, but didn’t explain how you access it. Similar to blocks, we offer a useFlow hook as the primary mechanism for accessing and transitioning flows. The hooks type definition is below.
interface Flow<T> { readonly kind: "flow"; readonly type: T; readonly uid: string; readonly sid: string; readonly version: number; readonly state: { started: boolean; completed: boolean; exited: boolean; }; readonly blocks: Block[];}
interface FlowIntention { complete: () => void; reset: () => void; start: () => void; exit: () => void;}
const useFlow: (uid: Flow['sid']) => [flow: Flow, intent: FlowIntention]The most powerful concept here is that the flow has references to its blocks—meaning that you can use this hook to access all state for a flow (its state and the state of its blocks) and get live updates as that state changes.
You might have noted in the type definitions above that the type property on the flow and block interfaces is generic—this is to support us building and exposing new block types.
In closing
We think these changes create a stable and sensible foundation to build upon moving forwards. We are excited to keep iterating on our SDKs, building and exposing concepts that will provide value to our awesome customers.